Allsvenskan är slut och på sina håll görs diverse summeringar. Under året har jag med hjälp av egen programkod simulerat matcher och beräknat så kallade förväntade poäng (expected points, xP) och jämfört dessa med de faktiska poäng som lagen tar under säsongen. Namnet expected points är dock något missvisande, för xP mäter inte riktigt samma sak som faktiska poäng. Faktiska poäng mäter utfall medan xP i någon mån mäter prestation, lite beroende på vilken modell man använder för att beräkna dem.
Hur beräknas xP? Detta beror som sagt på modellen som används. Tanken bakom xP är att om vi tänker oss att vi spelade om en match som hade en given chansmässig utgång många gånger, hur ofta skulle matchen sluta i vinst för det ena eller det andra laget, eller med kryss? Baserat på den chansmässiga fördelningen i en match, och ibland i kombination med andra mått, simuleras matchen ett visst antal gånger för att ta reda på vinstfrekvenserna för båda lagen samt kryssfrekvensen. Hur detta går till utgår från ett antal matematiska antaganden som inte behöver gås in på här. Ett exempel: antag att lag 1 enligt simuleringarna vann 40% av gångerna, lag 2 vann 35% av gångerna och man kryssade i 25% av fallen. En seger är ju värd 3 poäng och ett kryss 1 poäng, så lag 1 skulle då få 0,4*3+0,25*1=1,45 xP, och lag 2 får 0,35*3+0,25=1,3 xP. Traditionellt beräknas xP i de flesta modeller endast genom att simulera matchen genom xG-fördelningen i en match, och det är på detta sätt jag har gjort. Fler parametrar kan dock adderas till modellen för att på andra sätt beskriva vinstsannolikhet och prestation, vilket exempelvis PlaymakerAI:s modell gör som vi kommer jämföra med senare. Exempel på sådana diskuterade jag i denna text för den intresserade.
Efter 30 omgångar av allsvenskan 2023 har vi följande xP-tabell, där xP också jämförs med de faktiska poängen, samt differensen poäng minus xP. En positiv differens innebär således fler tagna poäng än xP, och tvärtom. En positiv differens implicerar i någon mån en överprestation i utdelning sett till de lägen man skapat och släppt till. All xG-data kommer från Twelve football.

Vi märker flera större differenser mellan de faktiska poängen och xP denna säsong (mer om detaljerna bakom detta i slutet av texten). Störst positiv differens står Elfsborg för, följt av Kalmar, Hammarby, Värnamo och Malmö. Störst negativ differens står Varberg för, följt av BP, AIK, Blåvitt, Degerfors och Sirius. De största utropstecknen är givetvis AIK, Blåvitt och Sirius sett till säsongens resultatmässiga prestationer som helhet, och åt andra hållet handlar det framförallt om Hammarby och Kalmar som i sina matcher hade god utdelning åt båda håll och fick ett mycket bra utfall under säsongen sett till de chansskaparmässiga prestationerna. Bäst utdelning hade dock Elfsborg, ganska överlägset. Malmö slutar i topp ganska också ganska överlägset precis som Varberg slutar i botten totalt överlägset. AIK och Blåvitt har legat där uppe i princip konstant under säsongen, men ett lag som dalat rejält är BP som låg på cirka +-0 i slutet på våren, men har haft riktigt dålig utdelning under sommaren och hösten.
Vi kan även studera lagens snitt under säsongen. I samband med att xP har beräknats har givetvis även lagens vinstsannolikheter för varje match beräknats. Lagens snitt per match redovisas här nedan.

Zoomar vi in lite extra noga på Blåvitts poängmässiga utveckling under säsongen kan vi betrakta följande graf.

Under säsongsinledningen drog givetvis xP ifrån då det blev idel nollor i poängkolumnen i april, men när man började ta poäng under maj månad började poäng och xP öka i samma takt och man fick utfall enligt de chansmässiga prestationerna. Sedan kom den tröga sommaren utdelningen var ett av de största problemen, och gapet mellan xP och poäng var som störst efter Elfsborg borta 16 juli. Därefter har de chansskaparmässiga prestationerna framåt och bakåt varit relativt linjära utan större toppar och dalar, samtidigt som utdelningen äntligen började komma i augusti och september, och poängen började konvergera mot xP, för att skillnaden till sist skulle öka igen efter den senhöst vi nu haft
Vidare kan vi även titta på en graf över ett rullande medelvärde över förväntade poäng under säsongen för att kunna identifiera de perioder som man stod för de chansmässigt bästa prestationerna när offensiv och defensiv kombineras.

Här kan vi lite tydligare se vilka perioder som var de bättre gällande den chansmässiga fördelningen under året. Det rullande medelvärdet har beräknats per tre matcher. Vi ser att man ökade rejält i prestation under den sena våren och nådde bra nivåer, men utdelningen var som sagt det som hämmade oss. Under mitten av sommaren kom de rejäla dipparna, och det blev tydligt att vi hade problem att skapa chanser framåt och lägre xP följde således i dessa matcher. Sedan ser vi återigen ett tydligt uppsving i prestation under sommar och tidig höst för att nå sin topp runt BP hemma, Mjällby borta och Hammarby borta (märk väl att xP tar in motståndarlagens skapade chanser också – även om vi inte skapade allt för mycket de matcherna gjorde inte motståndarna det heller, samt att vi fick två straffar dessa tre matcher). Precis som resultaten sjönk de chansmässiga prestationerna under senhösten. Det jag framförallt tar mig är vad som hade kunnat ske om utdelningen kommit under senvåren när prestationerna blivit mycket bättre. Där spelar avslutskvaliteten och slumpen en större roll, och den hade vi inte då.
Återgår vi nu till det bredare allsvenska perspektivet så har vi sett att det finns både stora positiva och negativa skillnader i flera fall under årets allsvenska säsong. Man skulle kunna tro att detta tyder på att xP inte är en bra indikator på att ”förutspå” faktiska poäng, men detta stämmer inte riktigt. Variansen i xP, som är en följd av variansen i avvikelser mellan gjorda mål och skapat xG, är för stor under en enskild säsong för att kunna dra en sådan slutsats endast baserad på en säsongs data. Vi kan titta under längre tid. Utför vi en korrelationsmätning mellan xG och faktiska poäng under de senaste sex säsongerna i Europas fem största ligor (således totalt 30 säsonger, totalt 11 160 matcher, knappt 300 000 avslut) finner vi en korrelation på 0,829, där värdet 1 är en perfekt korrelation. Beroendet är således starkt. Jämför vi på samma dataset förhållandet mellan xG och gjorda mål finner vi att det under dessa säsonger går 0,97 xG på ett mål.
Det finns givetvis invändningar. Om det finns en stor varians i avvikelsen mellan xP och poäng under en enskild säsong enligt resonemanget ovan, vad är då poängen med att göra en sådan tabell för en enskild säsong? Syftet med tabellen bör inte vara att använda den som någon sorts ”objektiv sanning”, eller en standard för hur serien ”borde” slutat. Som sagt i inledningen, xP och poäng mäter två olika saker – prestation respektive utfall. Det är alltså viktigt att komma ihåg att xP aldrig mäter utfall, varför den inte bör användas som ett ”facit” när man talar om säsongen ur ett utfallsperspektiv. Tabellen bör istället användas som en indikator för lagen att kunna identifiera att man kanske inte presterade så bra i matcherna som den slutgiltiga poängmässiga tabellen visade och därför behöver ändra på saker och ting, och tvärtom. I slutändan kommer dock slumpmässigheten i avslutsläget alltid att finnas där som är svår att göra något drastiskt åt och som är en så stor del i att tabellen inte slutar på samma sätt varje år, trots att vissa lag objektivt är bättre än andra.
I inledningen nämndes att dataföretaget Playmaker har en annan xP-modell som även tar in andra parametrar i modellen. När man omdefinierade sin modell valde man att även lägga till expected threat (xT) och bollinnehav som parametrar för att även ta hänsyn till matchdominans på sätt som inte nödvändigtvis reflekteras i xG-fördelningen. Denna justering förbättrar modellens korrelation med faktiska poäng marginellt, men den huvudsakliga vinningen är att den kan anses mer realistisk då spelmässig dominans intuitivt spelar roll i sannolikheten för att ett lag ska vinna en match, även om den dominansen inte nödvändigtvis reflekteras i den chansmässiga fördelningen. Tyvärr finns inte offentlig tillgång till Playmakers xP-tabell efter omgång 30, men jag har funnit motsvarande tabell efter omgång 27 som vi kan jämföra den xG-baserade modellen med.
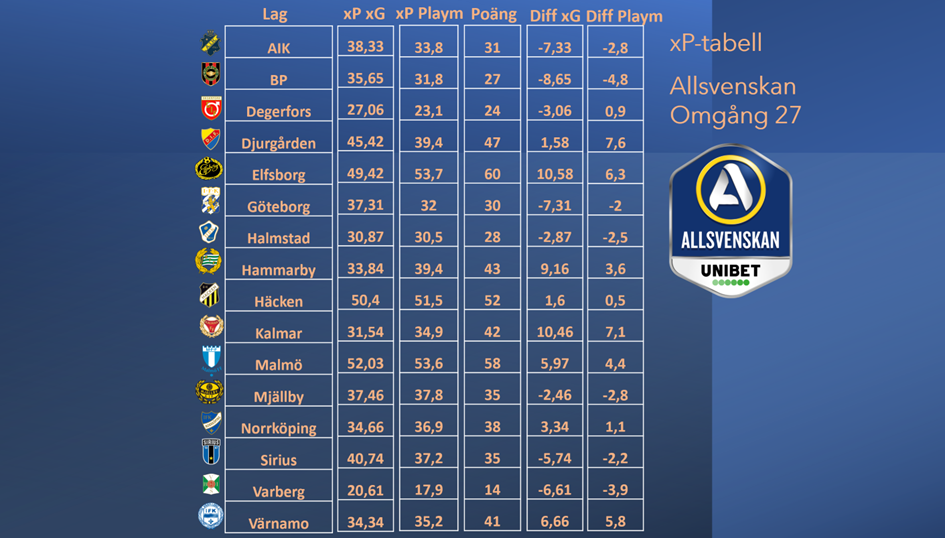
Målet med en xP-modell bör givetvis vara att komma så nära faktiska poäng som möjligt. Vi ser att Playmakers xP-modell differenser mot poäng generellt är mindre än mot modellen som är baserad på xG. Gör vi en korrelationsmätning ser vi att Playmakers modell mäter 0,91 jämfört med xG-baserade på modellen på 0,73. Playmakers modell visade sig mycket närmare utfallet denna säsong. Vi ska dock akta oss för att endast utifrån detta konstatera att Playmakers modell alltid är bättre. Men som man själva skriver i sin text – även om förbättringen märks mindre på ett större dataset är Playmakers modell ett bättre mått på underliggande prestation då den tar hänsyn till fler parametrar. Bland de parametrar som undersöktes här gällande korrelation med poäng finner vi passningar till box och touches i box som parametrar som skulle kunna förbättra modellen och som kan implementeras till kommande säsonger.